

In the rapidly shifting landscape of 2026, the question isn't just about which tool can show you a graph; it’s about which ecosystem can handle the explosive growth of AI-driven infrastructure and decentralized data. As teams face mounting pressure to consolidate tools while maintaining deep visibility, the choice between a modular, open-source-first approach and a unified, proprietary powerhouse has never been more critical.
Modern observability has evolved into a strategic pillar where Autonomous IT and Adaptive Telemetry are no longer buzzwords but requirements. Organizations are moving away from passive monitoring toward systems that proactively predict failures using agentic AI. Whether you are managing complex LLM workflows or scaling a global Kubernetes mesh, the decision between these two giants defines your team's operational velocity. Today, the debate centers on finding the balance between the "instant-on" convenience of a managed SaaS and the long-term sovereignty of an open, interoperable stack.
The Evolution of Observability in 2026: Navigating the Grafana vs Datadog Era
The current era of "Observability 2.0" has moved past simple monitoring. Today, we are seeing a massive shift toward Adaptive Telemetry, the ability for platforms to intelligently filter and prioritize data based on its actual value rather than just its volume. Engineering teams are no longer satisfied with "black box" pricing; they want granular control over what they ingest. In the context of the Grafana vs Datadog debate, this shift is critical: one focuses on curated automation, while the other empowers you with total structural control.
The Shift from Data Volume to Data Value
By 2026, the "collect everything" mentality will have become a financial liability. Organizations are now utilizing Intelligent Sampling to manage the 50–80% of telemetry that is historically "dark" or never used for an alert. Modern platforms now use machine learning to identify repetitive logs like heartbeat messages or health checks and deduplicate them at the source. This ensures that when you compare these platforms, the winner isn't the one that stores the most data, but the one that reveals the most insight for the lowest overhead.
Zero-Code Visibility with eBPF
One of the most significant updates in 2026 is the maturity of eBPF-based instrumentation. Gone are the days of manually "sprinkling" tracing code across hundreds of files. Whether you lean toward the open-source flexibility of one or the managed efficiency of the other, both ecosystems now leverage eBPF to hook into the Linux kernel. This provides "Golden Signals" (Rate, Errors, Duration) and deep network visibility without a single line of code change, effectively democratizing deep-stack observability for legacy and modern apps alike.
The Rise of Observability as Code (OaC)
Furthermore, the rise of Observability as Code (OaC) has fundamentally changed how we interact with these platforms. Tools are now expected to integrate directly into Git-based workflows, allowing dashboards and alerts to be versioned, reviewed, and deployed just like application code. This "shift-left" approach means:
- Predictable Deployments: Dashboard changes are peer-reviewed before going live.
- Scalable Governance: Consistency is maintained across thousands of microservices via standardized templates.
- Disaster Recovery: Your entire monitoring state is backed up in a repository, not trapped in a vendor's UI.
In this high-stakes environment, choosing between these platforms means deciding whether you want an AI-led, autonomous experience or a developer-centric, programmable one.
Breaking Down the Core Philosophy of Grafana vs Datadog
In 2026, the divide between these two platforms has crystallized into two distinct paths: Autonomous Intelligence vs. Engineered Flexibility. While both have integrated advanced AI, the way they expect your team to interact with data remains fundamentally different.
The Managed Powerhouse: Datadog
Datadog remains the "gold standard" for teams that want a zero-friction, out-of-the-box experience. In 2026, it doubled down on its Watchdog AI and the new Bits AI SRE agent, which function as proactive collaborators rather than just alerting tools.
- Autonomous Root Cause Analysis (RCA):
It doesn't just alert you that a service is down; it analyzes traces, logs, and recent code deployments to suggest the most likely root cause. It can even propose code fixes or trigger auto-rollbacks of faulty deployments before an engineer opens a terminal. This predictive engine leverages a multi-trillion-point dataset to recognize patterns that precede a crash, effectively shifting your team from reactive firefighting to proactive system hardening. By the time a human is paged, the AI has already correlated the infrastructure spike with a specific GitHub pull request and mapped out the blast radius across your microservices.
- The "Single Pane of Glass" Advantage:
Because the platform owns the entire stack from the agent on the host to the storage backend, the correlation between a spike in CPU and a specific line of code in a trace is seamless. This tight coupling eliminates the "context switch tax" that plagues modular systems. In 2026, this integration extends to the network layer, allowing you to visualize how cloud-provider outages or DNS latencies are impacting individual user sessions in real-time, all within a unified interface that requires zero manual mapping.
- Agentic Workflows:
With the 2026 updates, Datadog's AI can now participate in Slack or Teams incidents, summarizing the impact and identifying the exact users affected by an error in real-time. These autonomous agents act as a digital "first responder," pulling relevant graphs into your chat threads and querying logs based on natural language prompts. This level of automation ensures that even junior engineers can navigate complex outages with the insight of a veteran SRE, as the tool effectively narrates the story of the failure as it unfolds.
The Flexible Architect: Grafana
Grafana, particularly with the release of version 12, has evolved from a visualization layer into a comprehensive "LGTM" (Loki, Grafana, Tempo, Mimir) stack. Its primary strength in 2026 is composability and the "Big Tent" philosophy.
- Logical Data Management:
Unlike platforms that require you to ingest everything into their proprietary silo, Grafana allows you to "bring your own data." Using SQL Expressions, you can query and join information across multi-cloud environments (like Snowflake, BigQuery, and Databricks) in real-time without moving a single byte. This data-source-agnostic approach is essential for the 2026 enterprise, where data lives in various specialized lakes. You can now create a single panel that visualizes your application's error rate alongside your real-time revenue loss from a separate business database, providing a "holistic view" that is impossible when data is locked in a vendor's vault.
- Observability as Code (OaC):
The introduction of Git Sync and the GrafanaCTL tool allows teams to treat their observability platform as a programmable asset. Dashboards and alert rules are now version-controlled in GitHub, ensuring that your monitoring evolves alongside your application code. In 2026, this means your observability setup is self-healing; if a dashboard is accidentally deleted or altered, the Git-based source of truth automatically restores it. This workflow fosters a culture of "Monitoring as a Product," where engineers can contribute to visibility tools using the same CI/CD pipelines they use for their primary software.
- Vendor Neutrality & OpenTelemetry:
For organizations prioritizing OpenTelemetry (OTel) standards, it is the natural home. It avoids vendor lock-in by supporting a plug-and-play architecture where you can swap out backends without losing your front-end visualizations. In the 2026 landscape, being "OTel-native" means you can leverage the industry's best-of-breed storage solutions while maintaining a consistent user experience. This flexibility ensures that you are never held hostage by rising storage costs or shifting vendor priorities, as your telemetry pipelines remain entirely under your control.
Core Comparison Points at a Glance:
- Implementation Speed:
Datadog wins for "Time to Value." You install an agent, and 5 minutes later, you have 750+ integrations working. The platform's auto-discovery features instantly map your entire container landscape, identifying databases, caches, and web servers without any manual YAML configuration. This makes it the ideal choice for hyper-growth startups where engineering time is the most expensive resource.
- Customization Power:
Grafana wins for "Bespoke Insights." If you need to overlay business sales data from a SQL database on top of your Kubernetes cluster health, it makes this easy. Its vast plugin ecosystem and the ability to write custom transformations allow you to bend the platform to your specific business logic, rather than forcing your business to fit into a vendor's pre-defined monitoring templates.
- Operational Burden:
Datadog is fully managed (SaaS), meaning they handle the scaling, security updates, and data retention logic. This "hands-off" approach is perfect for teams that want to focus exclusively on their core product. In contrast, while the Cloud version offers a managed experience, the self-hosted option remains the gold standard for those in highly regulated industries like finance or defense who need absolute data sovereignty and the ability to run their entire monitoring stack within an air-gapped environment.
Hire DevOps Engineers Today!

The Rise of AI Observability and LLM Monitoring: Grafana vs Datadog
As we move through 2026, the biggest differentiator between these two is how they handle the "AI Stack." Monitoring a standard microservice is one thing; monitoring an Agentic AI workflow where models make autonomous decisions, call external tools, and chain multiple prompts is another. The challenge has shifted from tracking "uptime" to tracking "intent" and "accuracy."
Datadog’s Approach: Managed Intelligence
Datadog has introduced LLM Obs, a specialized suite that tracks token usage, prompt latency, and model "hallucination" scores out of the box. It’s perfect for teams that are shipping AI features fast and need immediate guardrails without building their own custom scrapers.
- Integrated LLM Evaluations:
Using the "LLM-as-a-judge" pattern, the platform can automatically score responses for toxicity, bias, and factual alignment. This data is correlated directly with your APM traces, so you can see if a specific database latency caused a model to "hallucinate" due to a timeout.
- Prompt Tracking & Versioning:
You can now monitor how different versions of a prompt affect performance. If a new prompt template increases token costs by 20% or spikes latency, the platform flags it as a "prompt regression," treating your natural language instructions with the same version-control rigor as source code.
- Agentic Workflow Tracing:
For complex AI agents, it provides a "Workflow View" that maps out the entire chain of thought from the initial user query to the final tool execution, identifying exactly where a logic loop or an API failure occurred.
Grafana’s Approach: The Open Standard
The community has leaned heavily into OpenTelemetry (OTel) GenAI standards. Using specialized exporters and the Grafana LLM plugin, you can pipe model performance data into your existing dashboards. While it requires more manual setup, it gives you the freedom to monitor local, self-hosted models (like Llama 4) just as easily as third-party APIs.
- Self-Hosted Sovereignty:
Many enterprises in 2026 are moving AI workloads on-premises for security. Grafana excels here by integrating natively with inference engines like vLLM and Ollama. You can track GPU cache utilization, queue depth, and KV cache efficiency metrics that proprietary SaaS tools often struggle to reach in private environments.
- Custom Evaluation Pipelines:
Instead of using a pre-packaged judge, the "Big Tent" philosophy allows you to use open-source evaluation frameworks like OpenLIT. You can visualize hallucination detection and bias assessment alongside your system-level metrics, creating a unified view of "Model Health" vs "Infra Health."
- Adaptive Cost Dashboards:
Leveraging its flexible querying, Grafana allows you to build custom FinOps dashboards that calculate the "Cost-per-Outcome." By joining token usage from your logs with your actual cloud billing data, you can see the exact ROI of every AI feature you deploy.
FinOps and the War on Observability Costs: Grafana vs Datadog
In 2026, "Observability Bills" have moved from a minor line item in the IT budget to a primary boardroom discussion. The era of "log everything and figure it out later" is officially over because the sheer volume of data generated by modern distributed systems is breaking infrastructure budgets. Companies are now adopting FinOps for Observability, treating telemetry data with the same fiscal rigor as cloud compute or storage. In the Grafana vs Datadog landscape, this has sparked a race to provide the most effective cost-reduction tools without sacrificing system safety.
Adaptive Metrics in Grafana: The Cardinality Killer
This feature has become a game-changer for teams struggling with "metric bloat." It automatically identifies "cold" metrics data points that are being ingested at high frequency but are never actually viewed on a dashboard, used in an alert, or queried by an engineer.
- Intelligence-Driven Aggregation:
Rather than simply deleting data, it suggests aggregation rules that condense low-value, high-cardinality data into high-level summaries. This allows teams to cut their cloud bills by up to 40% while retaining the necessary signals for long-term trend analysis. By reducing the storage footprint of metrics that provide no unique insight, organizations can reinvest those savings into deeper tracing or security monitoring.
- Safe-to-Apply Recommendations:
In 2026, the tool uses machine learning to ensure that any proposed aggregation won't "break" existing Prometheus queries or recording rules. It provides a "dry run" view, showing exactly how much you will save before you commit to the change. This proactive validation ensures that SRE teams can optimize costs without the fear of losing critical visibility during a future incident.
- Dynamic Exemption Lists:
Critical services can be shielded from aggregation through automated exemptions, ensuring that your most sensitive "Tier 0" applications always maintain full-fidelity, raw telemetry regardless of cost-saving policies. This level of granular control means FinOps policies can be applied globally while respecting the unique reliability requirements of individual engineering pods.
Datadog’s Intelligent Ingestion: Tiered Visibility
Datadog has countered the cost crisis with Flex Logs, a sophisticated storage tiering system that challenges the traditional "index everything" model. It allows you to store high-volume logs in low-cost storage and only "re-hydrate" or index them when you actually need to investigate a specific incident.
- Log Forwarding & Selective Indexing:
You can now ingest 100% of your logs for real-time tailing and live troubleshooting, but choose to only index 10% for long-term search. This "split-brain" ingestion model ensures you have eyes on the ground during a crisis without paying for the permanent storage of "info" level logs that provide little value. This allows for a "Logging without Limits" philosophy that is finally decoupled from a "Budget without Limits" reality.
- The Flex Tier Advantage:
In 2026, Flex Logs provides a "middle ground" storage option that remains searchable at a fraction of the cost of standard indexing. Leveraging commodity object storage backends allows for years of retention essential for compliance and forensic audits without the ballooning costs associated with traditional log management. This tiering effectively turns your log repository into a searchable archive that scales with your business growth rather than your data volume.
- Automated Sensitive Data Scanner:
Part of the cost-saving strategy involves the Sensitive Data Scanner, which proactively identifies and masks PII (Personally Identifiable Information) or high-cardinality noise at the edge. By scrubbing useless or risky data before it ever hits the storage layer, teams can significantly reduce the "tax" paid on dirty or repetitive data. This also streamlines compliance, as data is cleaned at the point of ingestion rather than being managed manually after it has already cost you money to store.
Hire DevOps Engineers Today!
Comparing Key Capabilities: Grafana vs Datadog
In 2026, the gap between "managed convenience" and "flexible engineering" has widened. Choosing between these platforms now requires a look at how they handle the day-to-day realities of modern DevOps from the first line of instrumentation to long-term data governance.
1. Setup and Ease of Use: Time-to-Value vs. Precision Control
Datadog:
- Instant Discovery: Datadog remains the undisputed leader for organizations prioritizing speed. Its proprietary agent is designed for auto-discovery; once installed on a cluster or host, it instantly identifies databases, containers, and web servers, populating hundreds of pre-built dashboards within minutes.
- Low Operational Overhead: As a pure SaaS platform, Datadog handles all the "boring" work, scaling the backend, software upgrades, and data replication. This "buy-not-build" approach is ideal for teams that cannot afford the engineering hours required to architect a custom monitoring system.
Grafana:
- OTel Optimization: The Grafana Stack (specifically Grafana Cloud) has shifted its focus to OpenTelemetry (OTel) optimization. While it requires more initial configuration, in mapping your telemetry pipelines and defining your data backends (Loki, Mimir, Tempo), it rewards you with a system tailored precisely to your infrastructure.
- Precise Instrumentation: In 2026, Grafana introduced "Quickstart Packs" and auto-instrumentation tools like Grafana Beyla (eBPF) to bridge the setup gap. However, it still caters to the "power user" who wants to know exactly how their data is being handled and avoid proprietary agent bloat.
2. Intelligence and Automation: Proactive Agents vs. Cost Insights
Datadog:
- Watchdog AI & Bits AI: Datadog has transitioned from a monitoring tool to an AI-driven collaborator. Its Watchdog AI and Bits AI SRE agent don't just find errors; they provide narrative summaries of incidents.
- Autonomous RCA: In 2026, Datadog’s intelligence is focused on Root Cause Analysis (RCA), automatically correlating a spike in p99 latency with a specific code deployment or a cloud provider's regional outage. It effectively narrativizes the "story" of a crash before your team even starts a bridge call.
Grafana:
- Operational Efficiency: Grafana’s intelligence has taken a different route, focusing on Operational Efficiency. Its "Adaptive Telemetry" suite (including Adaptive Metrics and Adaptive Traces) uses machine learning to scan your ingestion patterns and identify "dark data."
- Cost-Aware AI: Instead of just fixing bugs, Grafana’s AI helps you fix your budget. By identifying metrics that cost money but are never queried, it provides a transparent look at the value of every byte you ingest, ensuring your observability ROI remains high.
3. Customization and Ecosystem: The "Single Pane" vs. The "Big Tent"
Datadog:
- Seamless Integration: Datadog offers a unified, proprietary experience. Because they control the agent, the backend, and the UI, the integration is flawless. You can click on an error in a log and immediately see the corresponding trace and host metrics without any manual mapping.
- Ecosystem Limits: However, you are largely confined to the Datadog ecosystem. Pulling in external data from a specialized business database or a third-party security tool can be cumbersome and often requires you to ingest that data into Datadog first, incurring extra costs.
Grafana:
- "Big Tent" Philosophy: Grafana thrives on its ability to be the "manager of managers." It is the only platform in 2026 that truly allows you to mix data from 100+ sources, such as SQL, Snowflake, and even Datadog itself, within a single dashboard.
- Visual Power: This makes Grafana the superior choice for high-level executive views that span multiple clouds, on-premise servers, and even business intelligence tools, all without needing to migrate the underlying data.
4. Workflow and Deployment: UI-First vs. Observability as Code
Datadog:
- World-Class UI: Datadog provides a polished UI that is accessible to both developers and non-technical stakeholders. Its drag-and-drop builders and "notebooks" make it easy to collaborate during an incident.
- SaaS Dependency: While it has robust API support, the primary experience is designed to be managed through their managed SaaS portal. This is perfect for teams that want a consistent, vendor-managed interface.
Grafana:
- Observability as Code (OaC): Grafana has fully embraced the GitOps movement. In 2026, advanced teams manage their Grafana instance like a software project. With native Git Sync, every dashboard and alert rule is version-controlled in GitHub.
- Programmable Asset: This allows for peer reviews of monitoring changes and ensures that if a service scales to a new region, its observability follows automatically via CI/CD pipelines. This workflow is a major draw for engineering-heavy cultures.
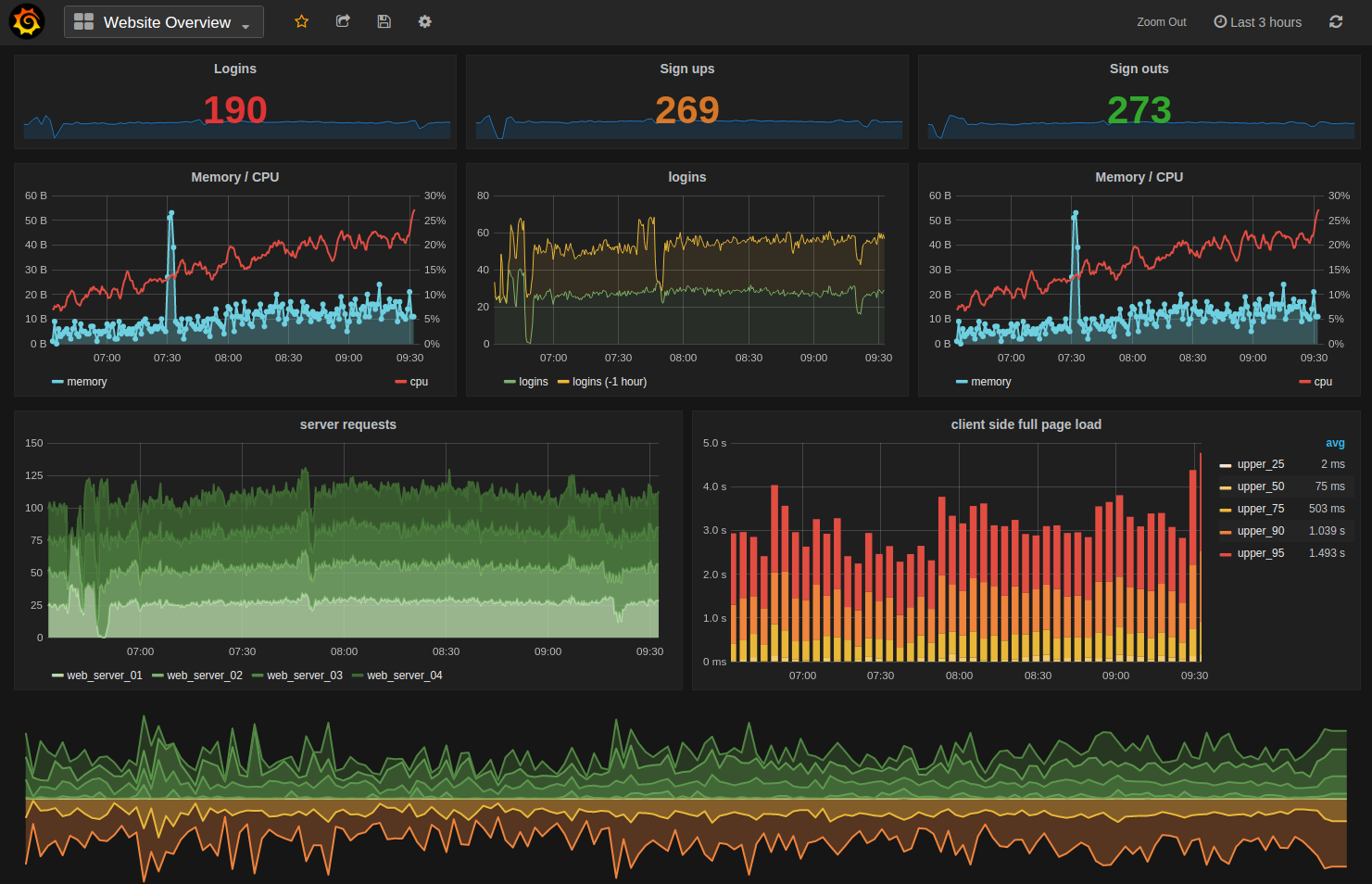
Beginner Example: How Setup Looks
Grafana Setup (Basic)
- Install Prometheus (collect metrics)
- Install Grafana
- Connect Prometheus to Grafana
- Create a dashboard
- Set up alerts (optional)
Datadog Setup (Basic)
- Sign up on Datadog.com
- Install the Datadog agent on your server
- See metrics/logs in the dashboard instantly
- Create alerts and enable APM

Conclusion
The battle of Grafana vs Datadog in 2026 is no longer about which tool has better graphs, but about which philosophy aligns with your organizational DNA. If your priority is rapid scaling, out-of-the-box AI-driven root cause analysis, and a hands-off managed experience, Datadog remains the premier powerhouse. However, if you demand total data sovereignty, vendor neutrality through OpenTelemetry, and the ability to unify diverse data sources under a single "Big Tent," the Grafana stack offers unparalleled flexibility.
Ultimately, navigating these complex observability landscapes requires more than just the right software; it requires the right expertise to implement and tune these systems for maximum ROI. If you are looking to architect a high-performance, cost-effective monitoring strategy, now is the time to Hire DevOps Engineers who understand the nuances of modern telemetry.
Ready to transform your infrastructure visibility? Contact Zignuts today to discuss your project requirements and let our experts help you build a future-proof observability stack.

Margi Dadhania
DevOps Enthusiast - Focused on building reliable, scalable systems and streamlining deployment processes to deliver smooth and efficient application performance.


