Engineering High-Performance, Scalable & Secure Digital Platforms
In the fast-evolving landscape of 2026, organizations require more than just speed; they need intelligent, self-healing, and value-driven systems. At Zignuts, we have transitioned from traditional automation to a sophisticated culture of platform engineering and AIOps. By integrating advanced machine learning with established methodologies across AWS, GCP, Azure, and Kubernetes, we build digital ecosystems that are not only resilient but also capable of predictive adaptation.
Our approach recognizes that modern infrastructure is no longer a static asset but a dynamic organism that must respond to real-time market shifts and security threats. By converging development, security, and operations into a unified, high-velocity stream, we eliminate the friction that historically slowed down innovation. We focus on creating cognitive environments where manual intervention is minimized and strategic creativity is maximized.
This updated 2026 guide reflects our commitment to modern engineering standards, featuring the latest strategies in autonomous pipelines and zero-trust cloud architectures. We empower businesses to transcend basic cloud adoption, helping them achieve true operational sovereignty through data-driven insights and hyper-automated delivery frameworks.
Infrastructure as Code (IaC): The Foundation of Reliable Cloud Engineering
DevOps Best Practices
In 2026, we view infrastructure as a living software product. Utilizing the latest versions of Terraform, Crossplane, and OpenTofu, we ensure that every cloud environment is fully reproducible, audit-ready, and resilient to configuration drift. We have moved beyond simple provisioning to Intent-Driven Infrastructure, where the focus is on maintaining a desired state through continuous, autonomous reconciliation loops.
Our Core Strategies:
- Modular Terraform & OpenTofu Architecture: We build reusable, version-controlled modules with native OIDC for secure, passwordless cloud access, ensuring a DRY (Don't Repeat Yourself) codebase.
- Crossplane Control Planes: By turning Kubernetes clusters into universal control planes, we manage cloud resources (S3, RDS, VPCs) via the same K8s APIs used for applications, unifying the developer experience.
- Autonomous Drift Detection & Self-Remediation: Utilizing tools like Spacelift and Crossplane, our systems monitor environments 24/7. If a manual change occurs in the cloud console, the system automatically overwrites it to match the "source of truth" in Git.
- Policy-as-Code with OPA & Sentinel: Security and compliance are enforced at the pull request level. We use Open Policy Agent (OPA) to block non-compliant infrastructure (e.g., unencrypted buckets) before it is ever provisioned.
- Blueprint-based Scaling: From Edge locations to Core Data Centers, we use standardized blueprints to ensure environment parity across dev, stage, and prod.
- Immutable Infrastructure Mindset: We treat servers and clusters as temporary. Rather than patching a running system, we deploy a fresh, updated instance, eliminating the "snowflake server" problem.
- Dynamic Secret Injection: Using provider-backed vaults (HashiCorp Vault or AWS Secrets Manager), secrets are injected into the infrastructure at runtime and rotated automatically, reducing the risk of long-lived credential leaks.
Advanced IaC 2.0 Capabilities
Beyond standard provisioning, our 2026 framework integrates AIOps and Platform Engineering to further stabilize your digital ecosystem:
- Predictive Cost Modeling: Every infrastructure change includes an automated cost impact analysis in the Pull Request, preventing "sticker shock" from accidental over-provisioning.
- Ephemeral Environments: We automate the creation of "preview environments" for every feature branch, allowing developers to test against a production-like setup and destroying it once the PR is merged to save costs.
- State Encryption & Security: With OpenTofu, we implement state-file encryption at rest, ensuring that even the metadata of your infrastructure remains protected from unauthorized access.
What this means for clients:
- Rapid, One-Click Provisioning: Spin up entire global regions in minutes rather than weeks.
- Total Transparency: Every change is documented in Git, providing a clear audit trail for compliance (HIPAA, PCI-DSS, GDPR).
- Zero Manual Errors: Automation eliminates the risks associated with manual "point-and-click" configuration.
- Operational Sovereignty: Your team regains control over complex multi-cloud estates with a unified, code-based management layer.
Hire DevOps Engineers Today!

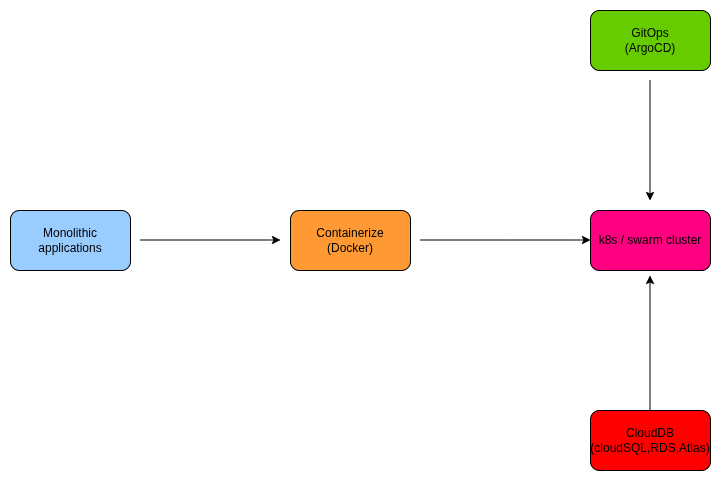
Multi-Cloud & Kubernetes Excellence
DevOps Best Practices
We architect modern, cloud-native platforms using EKS, GKE, and AKS, alongside advanced self-managed clusters for specific high-security needs. In 2026, our focus has shifted toward eBPF-powered networking and GPU-optimized workloads for AI-driven applications, ensuring that clusters are not just containers for code, but high-performance engines for innovation.
We specialize in abstracting the complexity of the underlying cloud provider, offering a consistent operational experience whether your workloads live on AWS, Azure, or Google Cloud. By leveraging Cluster API (CAPI), we treat Kubernetes clusters themselves as manageable resources, allowing for rapid lifecycle management across a global footprint.
Our Specialized Approach:
- Namespace-based Multi-tenancy: We implement strict logical isolation with resource quotas and limit ranges to prevent "noisy neighbor" issues in shared environments. This includes NetworkPolicies that default to a "deny-all" stance, ensuring that microservices only communicate over authorized paths, coupled with Hierarchical Namespaces (HNC) to manage complex organizational structures within a single cluster.
- Intelligent Auto-scaling with Karpenter & VPA: Beyond basic scaling, we use Karpenter for just-in-time node provisioning, which evaluates the specific requirements of pending pods to launch the most cost-effective instance type available. This is paired with Vertical Pod Autoscaler (VPA) to dynamically adjust CPU and memory reservations, preventing resource slack and ensuring application stability during unexpected load bursts.
- Advanced Traffic Management: We utilize Service Meshes for sophisticated traffic splitting, enabling Canary releases and Blue-Green deployments with automated health-check gatekeeping. This allows for fine-grained version shadowing and header-based routing, ensuring that new features are validated against real-world traffic patterns before a full global rollout.
- Zero-Trust Networking with Cilium: Using eBPF-based security policies via Cilium, we enforce transparent encryption and identity-based firewalling at the kernel level. This bypasses the overhead of traditional iptables, providing high-performance networking while securing the data plane against lateral movement within the cluster.
- Ambient Mesh Architectures: We implement sidecar-less service mesh models to reduce resource overhead and latency while maintaining full observability and mutual TLS (mTLS). By separating the proxying logic from the application pods, we simplify lifecycle management and eliminate the need to restart containers for mesh-related updates.
- Automated Disaster Recovery: We employ Velero and cross-region state replication to ensure your data and cluster configurations are recoverable within minutes of a regional failure. Our strategy includes regular automated recovery drills and persistent volume snapshots synced across geographic boundaries to maintain a near-zero Recovery Point Objective (RPO).
- GPU & AI Workload Optimization: We configure specialized node groups with NVIDIA operator support for LLM training and inference, ensuring high-throughput and low-latency data paths. This includes the implementation of Multi-Instance GPU (MIG) to slice large hardware units into smaller, isolated instances, maximizing the utilization of expensive AI compute resources.
Cloud-Native Orchestration 2.0
The 2026 standard for Kubernetes excellence goes beyond basic container management. We integrate Platform Engineering concepts to create a seamless developer internal portal:
- Cost-Aware Scheduling: Our clusters are configured to prioritize Spot Instances for fault-tolerant workloads, automatically switching to On-Demand capacity only when necessary to maintain service level objectives. We integrate real-time price feeds and interruption handling logic to migrate workloads gracefully before a spot instance is reclaimed by the provider.
- Unified Multi-Cluster Management: Using tools like Karmada or Anthos, we provide a single pane of glass to manage policies, deployments, and security across different geographical regions and cloud vendors. This centralization ensures that security patches and configuration changes are propagated globally in seconds, maintaining a consistent posture across the entire estate.
- Edge Kubernetes Integration: For applications requiring ultra-low latency, we extend the Kubernetes control plane to the edge, managing localized clusters that bring compute closer to the end-user. This involves optimizing K3s or MicroK8s distributions for resource-constrained environments while maintaining full compatibility with core CI/CD workflows.
The Strategic Impact:
- Unmatched Resiliency: High availability across multiple availability zones and cloud providers ensures your business stays online even during major provider outages. By distributing control planes and data planes intelligently, we mitigate the risk of a single point of failure at the infrastructure level.
- Operational Agility: Move workloads between clouds without rewriting deployment logic, avoiding vendor lock-in and taking advantage of provider-specific pricing. Our abstraction layers mean your developers interact with a standard API, regardless of whether the underlying hardware is in a private data center or a public cloud.
- Significant Cost Efficiency: Optimized compute usage through intelligent orchestration and aggressive spot instance utilization typically reduces waste by 30% or more. We provide granular visibility into spend per namespace and per team, fostering a culture of financial accountability within the engineering organization.
- High-Speed Delivery: Simplified management of complex, distributed microservices allows your engineering team to focus on building features rather than managing infrastructure. Automated "Golden Paths" ensure that a new service can go from initial code to a secured, monitored production environment in a matter of minutes.
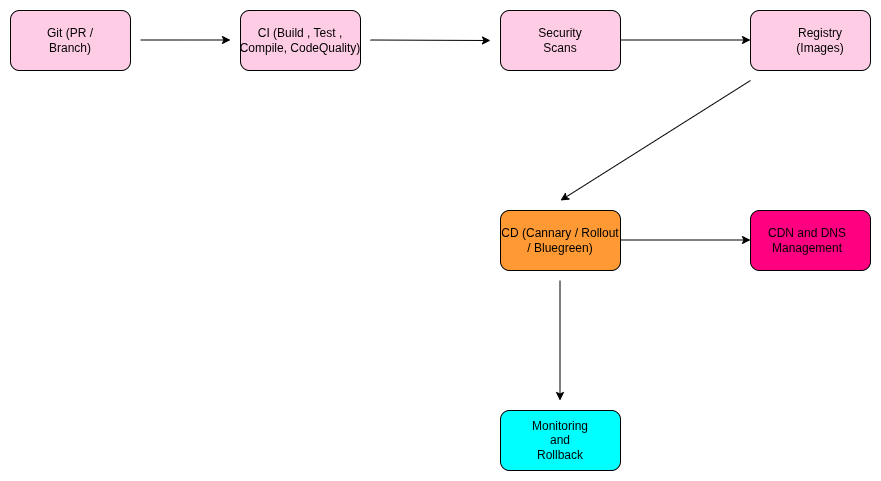
CI/CD Pipelines That Deliver with Zero Downtime
DevOps Best Practices
Our delivery pipelines have evolved into autonomous systems that use AI to verify code quality and deployment safety in real-time. In 2026, we have moved beyond simple "linear" pipelines to Progressive Delivery models that treat every release as a controlled, data-driven experiment. By leveraging ArgoCD and Argo Rollouts, we ensure that your software reaches production with the highest degree of confidence and zero impact on the end-user experience.
Advanced Tooling:
- Modern Orchestrators: GitHub Actions, GitLab CI, and ArgoCD for GitOps-based delivery.
- Progressive Release Tools: Argo Rollouts and Flagger for automated Canary and Blue-Green logic.
- AI Quality Guards: Launchable and SonarQube with AI-driven deep code analysis.
Our Operational Standards:
- AI-Powered Test Intelligence: We eliminate "test fatigue" by using machine learning to identify and run only the test suites affected by specific code changes. This reduces pipeline execution time by up to 70% without sacrificing coverage or quality.
- Automated DevSecOps Integration: Container scanning with Trivy and Snyk is a non-negotiable gate. Every build is automatically checked for vulnerabilities, misconfigurations, and license compliance before it ever touches a registry.
- GitOps Synchronicity: We ensure the cluster's actual state is a perfect mirror of the desired state defined in Git. Any manual "hotfixes" in the cluster are automatically detected and reverted to maintain a single source of truth.
- Predictive Rollback Mechanisms: Our pipelines don't just wait for a failure; they use AI to monitor logs and metrics during a rollout. If the system detects a 1% increase in latency or a subtle spike in 5xx errors, it triggers an Autonomous Rollback before the majority of users are affected.
- Standardized "Golden Paths": We provide developers with pre-approved, opinionated templates that bake in best practices for security, observability, and deployment. This "Paved Road" approach allows teams to go from a new repository to a live production service in minutes.
- Feature Flagging & Decoupled Releases: By integrating LaunchDarkly or Unleash, we separate deployment (pushing code to servers) from release (turning on features for users). This allows for dark launches and instant feature kills without requiring a full code rollback.
Progressive Delivery 2.0
In 2026, we will utilize Advanced Deployment Strategies to eliminate the "Big Bang" release risk:
- Canary Analysis with AI: We don't just shift traffic; we use automated analysis to compare "Canary" performance against the "Baseline" in real-time. If the AI sees a statistical deviation in system health, the rollout pauses or reverts instantly.
- Traffic Mirroring (Shadowing): For mission-critical updates, we mirror production traffic to the new version without the users ever seeing the response. This allows us to test how the new code handles real-world load and data without any risk to the live environment.
The Business Value:
- Drastically Reduced Time-to-Market: Ship features daily instead of monthly by removing manual approval bottlenecks.
- Minimized Deployment Risks: Continuous verification and automated safety nets catch errors before they become incidents.
- High Engineering Productivity: Automated developer self-service means your team spends 90% of their time building features and only 10% on "plumbing."
- Consistent and Reliable Releases: A unified process ensures that "it works on my machine" is a thing of the past, providing a stable experience for global users across all environments.
DevSecOps: Security Built Into Every Layer
DevOps Best Practices
In 2026, security is no longer a checkpoint; it is an integrated, continuous process. We follow a "Shift-Smart" approach where security guardrails are embedded directly into the developer workflow. By treating security as code, we ensure that every deployment is "secure-by-design" without introducing friction into the release cycle. Our framework utilizes AI-driven triaging to filter out up to 85% of security noise, allowing your engineers to focus on high-impact fixes rather than false positives.
Our Security Framework:
- Identity-First Security & Zero Trust: We implement least-privilege IAM policies paired with passwordless, OIDC-based cloud access and short-lived credentials. This ensures that even if a token is compromised, the window of risk is minimized.
- Automated SBOM & Supply Chain Transparency: We generate a Software Bill of Materials (SBOM) for every build, providing a complete manifest of open-source dependencies. This allows for instant impact analysis when a new zero-day vulnerability is announced in the global ecosystem.
- eBPF-Powered Runtime Threat Detection: Using tools like Tetragon or Falco, we monitor system calls at the kernel level. This allows us to detect and block unauthorized execution or data exfiltration in real-time, providing deep visibility into container behavior.
- AI-Driven WAF & DDoS Mitigation: Our cloud-native edge protection uses machine learning to differentiate between legitimate traffic spikes and sophisticated bot attacks, ensuring your services remain available under pressure.
- Continuous Compliance & Governance: We use Policy-as-Code (OPA/Kyverno) to automate compliance with standards like SOC2, GDPR, and ISO 42001. If a resource doesn't meet security requirements, it is blocked at the pipeline level.
- Automated AI Penetration Testing: We integrate continuous, agent-based security probing within staging environments to discover complex logic flaws that static scanners might miss.
The Security Outcome:
- Proactive Vulnerability Mitigation: Detect and patch issues in seconds, not weeks, with automated "one-click" PR fixes for vulnerable libraries.
- Global Compliance Readiness: Effortlessly meet modern AI-specific regulations and data residency requirements with automated audit trails.
Hire DevOps Engineers Today!
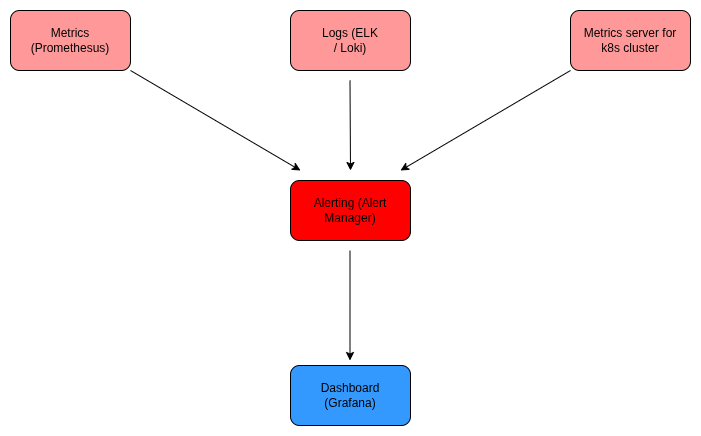
Observability: Full Visibility Across Systems
DevOps Best Practices
We move beyond traditional monitoring to Observability 2.0, focusing on actionable insights rather than just raw data. In 2026, the volume of telemetry data makes manual analysis impossible. We implement Telemetry Engineering to treat logs, metrics, and traces as high-value assets that are designed for correlation. By unifying these signals into a single, context-rich pipeline, we provide a holistic view of the customer journey rather than just server health.
Our Modern Stack:
- OpenTelemetry (OTel) Standard: We use OTel as the de facto standard for vendor-neutral data collection, ensuring you can switch analysis tools without re-instrumenting your code.
- Agentic AIOps: We deploy Autonomous AI Agents that investigate incidents independently. These agents correlate log patterns with trace spikes and suggest root causes before an engineer even logs into the dashboard.
- Unified Data Lakehouses: All telemetry flows into a centralized platform (Loki, ClickHouse, or ELK) optimized for high-cardinality data, allowing you to query millions of events in milliseconds.
- Business-Aligned SLOs: We map technical performance directly to business outcomes, such as user-journey completion rates or revenue impact during a latency spike.
The Operational Result:
- Instant Root Cause Identification: Reduce "war room" time by automatically connecting the dots between a recent deployment, a slow query, and a spike in error rates.
- Predictive Alerting: Move from static thresholds to AI-driven anomaly detection that identifies subtle system degradations before they impact the end-user.
- MTTR Reduction of 60-80%: High-fidelity tracing pinpoints the exact line of code or microservice causing a delay, allowing for rapid remediation.
FinOps: Intelligent Cost Optimization
DevOps Best Practices
Cloud spend is a critical metric. We ensure every dollar spent on cloud resources contributes directly to business value through rigorous financial operations. In 2026, FinOps has evolved into Continuous Cost Control, where cost is treated as a first-class engineering signal just like performance or security. We help you move from reactive "bill-shock" to proactive Unit Economics, understanding the exact cost of serving a single customer or an AI inference.
Our Cost Management Tactics:
- Dynamic Resource Rightsizing: We use AI to analyze historical usage and automatically adjust CPU/Memory limits, ensuring you aren't paying for "idle" capacity.
- Automated Storage & Data Tiering: Intelligent lifecycle rules move infrequently accessed logs and backups to "cold" storage tiers, significantly reducing long-term data costs.
- Spot Instance Orchestration: For non-critical and batch workloads, we aggressively use Spot/Preemptible instances with automated failover logic, cutting compute costs by up to 70%.
- AI Unit Economics & Attribution: We provide granular visibility into the marginal cost of AI features, tracking token usage and GPU hours per model version to ensure profitability at scale.
- "Focus-First" Cost Data: We normalize cost data across multi-cloud environments, providing a single source of truth for finance and engineering teams to collaborate.
- Automated Waste Removal: Our systems automatically identify and terminate "zombie" resources, unattached volumes, and abandoned staging environments outside of business hours.
The Financial Impact:
- Sustained Savings: Clients typically see a 25% to 45% reduction in cloud spend within the first quarter of implementation.
- Better Budget Forecasting: Move away from historical estimates to rolling, usage-driven forecasts that adapt as your application scales.
- Increased ROI: By eliminating waste, your cloud budget is redirected toward innovation and high-growth features.
Hire DevOps Engineers Today!
Real Case Studies: How We Solve Complex Challenges
DevOps Best Practices
In 2026, the theoretical benefits of modern engineering are proven through the successful execution of high-stakes digital transformations. At Zignuts, we go beyond simple tool implementation; we solve foundational business problems by aligning infrastructure with strategic goals. Below are the expanded journeys of how we partnered with global enterprises to achieve operational excellence.
Case Study 1: Multi-Cloud Kubernetes for Global SaaS
Problem: A leading SaaS provider struggled with a legacy VM-based monolith that was "fragile to change." Deployment failures were common, and scaling for global users required manual intervention that took hours. The lack of environment parity meant that bugs found in production were nearly impossible to reproduce in development.
Zignuts Solution:
- Microservices Decomposition: We led the refactoring of the monolith into domain-driven microservices containerized with Docker.
- Declarative GitOps with ArgoCD: We moved the entire delivery model to GitOps. In 2026, this means the infrastructure is self-healing; if a cluster state deviates from the Git repository, ArgoCD automatically reconciles it.
- Multi-Cloud Fabric: We designed a unified control plane using GKE (Google Cloud) and AKS (Azure), providing geographic redundancy and eliminating single-vendor dependency.
- Full-Stack Observability: Integrated OpenTelemetry with Prometheus and Grafana for deep-trace visibility into service-to-service communication.
Outcome:
- 99.995% System Uptime: Distributed workloads across clouds ensured that even a major provider outage wouldn't take the service offline.
- Deployment Velocity: Time-to-deploy was slashed from 45 minutes to under 4 minutes.
- 35% Cloud Cost Reduction: Moving from always-on VMs to right-sized Kubernetes pods allowed for significant savings through intelligent resource scheduling.
Case Study 2: DevSecOps Transformation for FinTech
Problem: A rapidly growing FinTech startup faced a "compliance wall." Manual security audits and fragmented IAM policies were delaying bi-weekly releases, making it impossible to keep up with market competitors. Furthermore, a high volume of open-source vulnerabilities was slowing down the engineering team.
Zignuts Solution:
- Automated Security Gates: We integrated Trivy and SonarQube directly into the Jenkins/GitHub Actions pipelines. Any code with high-severity vulnerabilities is now blocked automatically.
- Policy-as-Code (PaC): Using Open Policy Agent (OPA), we codified compliance requirements, ensuring that every cloud resource provisioned via Terraform meets the company's security baseline.
- Zero-Trust Identity: Implemented OIDC-based short-lived credentials, removing the need for long-lived "service account keys" that are prone to leaks.
- Real-time WAF & Audit Logging: Deployed Cloudflare WAF and centralized audit logs into a secure ELK stack for instant compliance reporting.
Outcome:
- 85% Reduction in Vulnerabilities: Proactive "shifting left" caught security flaws during the development phase rather than after deployment.
- Daily Production Releases: The team moved from bi-weekly "stress releases" to calm, automated daily deployments while remaining 100% compliant with industry regulations.
- Audit Readiness: What used to take weeks of manual evidence gathering is now a 5-minute automated report generation.
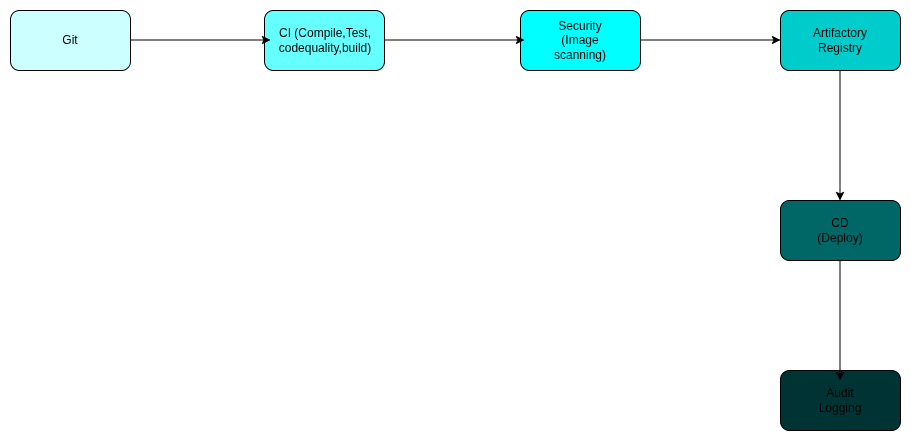
Case Study 3: High-Traffic Resilience for E-commerce
Problem: A global e-commerce platform experienced devastating revenue loss during flash sales. Traditional scaling was too slow to handle the "traffic tsunamis" that arrived in seconds, leading to database deadlocks and front-end timeouts.
Zignuts Solution:
- Predictive Autoscaling: We implemented Karpenter and the Horizontal Pod Autoscaler (HPA) using custom metrics (like active requests) rather than just CPU usage. This allowed the system to scale up before the traffic hit its peak.
- eBPF-Powered Performance: We replaced standard kube-proxy with Cilium eBPF, reducing network latency and improving throughput for high-volume transactions.
- Edge Caching Layer: Optimized Redis clusters and CloudFront distributions to offload 70% of read traffic from the primary database.
- Chaos Engineering: Conducted weekly "Game Days" using Gremlin to inject failures into the staging environment, ensuring the system’s self-healing mechanisms were battle-tested.
Outcome:
- Zero Downtime During 10x Spikes: Handled record-breaking Black Friday traffic with 100% platform stability.
- Seamless Scaling: The cluster grew from 5 nodes to 150 nodes and back down automatically, ensuring costs were only incurred when traffic was present.
- Revenue Growth: Stabilized customer experience led to a 22% increase in conversion rates during peak sales periods.
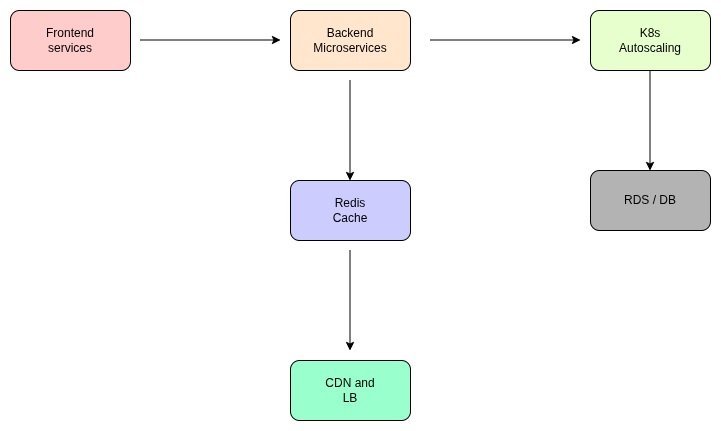
Conclusion
As we navigate the technological landscape of 2026, the boundary between infrastructure and software has completely dissolved. The transition from manual operations to intelligent, self-healing platforms is no longer an option; it is the baseline for survival. By adopting the advanced strategies outlined in this guide, from predictive AIOps and eBPF security to autonomous FinOps, organizations can move beyond mere cloud adoption to achieve true operational excellence. These practices ensure that your technology stack is not a cost center, but a resilient engine driving business growth and agility.
However, implementing these sophisticated frameworks requires deep technical insight and strategic foresight. To bridge the gap between complex tooling and business value, you need a partner who understands the intricacies of modern platform engineering. When you Hire DevOps Engineers from Zignuts, you gain access to a team of elite architects dedicated to building secure, scalable, and automated environments that empower your developers to innovate without friction.
Ready to future-proof your infrastructure and accelerate your delivery pipelines? Contact Zignuts today to discuss your project needs, and let’s build a high-performance digital ecosystem together.

Mangesh Vasekar
DevOps Enthusiast - Focused on building reliable, scalable systems and streamlining deployment processes to deliver smooth and efficient application performance.